
| Home / Indice sezione | www.icosaedro.it | |
 PHP e caratteri esotici
PHP e caratteri esoticiAggiornamenti:
2016-01-15 Aggiunto riferimenti alle librerie UTF8 e UString di PHPLint per una gestione più completa dell'Unicode.
Il linguaggio PHP si è ormai imposto come strumento per lo sviluppo di applicazioni WEB dinamiche. L'oggetto di questo articolo è come implementare il supporto per i caratteri delle varie lingue, dalle vocali accentate italiane alle lingue più esotiche. Discuteremo di:
L'Unicode
L'UTF-8
Charset ed encoding
Manipolare le stringhe
Manipolare i files
L'Euro
Impostare l'ambiente di sviluppo
Impostare il browser
Impostare il DB
Usando PostgreSQL
Usando MySQL
Generare l'output HTML dei dati
Impostare il PHP
Impostare il WEB server
Il dialogo tra browser, WEB server e DB server
Pagine HTML statiche
Verifica finale
Argomenti correlati
Riferimenti
Il charset Unicode comprende oltre 99'000 caratteri che coprono tutti i sistemi di scrittura conosciuti. I codici da 0 a 127 coincidono con quelli ASCII, e quindi i soliti codici di controllo come l'a-capo, il ritorno-carrello e la tabulazione orizzontale rimangono sempre gli stessi.
I codici Unicode, indicati come codepoint si possono codificare in modi diversi. Per ragioni di efficienza alcuni metodi di codifica usano 16 bit per carattere, che però non sono sufficienti per contenere l'intero insieme Unicode. Il consorzio Unicode ha perciò definito un sotto-insieme rappresentabile con 16 bit che si chiama basic multilingual plane (BMP). Il BMP comprende tutte le lingue di uso corrente.
La codifica più comune per il charset Unicode è l'UTF-8. L'UTF-8 viene descritto nell'RFC 3629, un documento che risale al 2003 ed è quindi piuttosto recente. Una spiegazione breve della codifica UTF-8 si trova nell'articolo Protocolli Internet - Seconda parte (www.icosaedro.it/articoli/protocolli2.html). L'UTF-8 è riconosciuto come l'encoding di interscambio default di Internet in sostituzione del vecchio ISO-8859-1.
L'UTF-8 fu inizialmente concepito per codificare l'intero charset UCS, e
le sequenze multi-byte potevano arrivare fino a sei byte. L'aggiornamento
RFC 3629 riduce le sequenze multi-byte a 4 byte al massimo, con i quali
si rappresentano codici Unicode fino a 21 bit. Come abbiamo detto, molti
sistemi e applicazioni correnti supportano solo il sotto-insieme a 16
bit del BMP per codificare il quale servono al massimo 3 byte in UTF-8.
Per esempio, la funzione qui sotto è la logica estensione della funzione
standard chr() ai codici Unicode limitato al BMP:
/**
* Returns an Unicode codepoint in its UTF-8 encoding.
* @param int $code BMP codepoint in the range from 0 up to 0xFFFF wiyh the only
* exception of the sub-range from 0xD800 up to 0xDFFF which is reserved for the
* UTF-16 encoding.
* @param string $invalid What to return if the codepoint is out of the BMP range.
* @return string UTF-8 encoded codepoint.
*/
function utf8_bmp_chr($code, $invalid = NULL)
{
if( $code < 0 ){
# negative
} else if( $code < 0x80 ){
return chr($code);
} else if( $code < 0x800 ){
return chr(0xC0 + ($code >> 6))
. chr(0x80 | $code & 0x3F);
} else if( $code < 0x10000 ){
if( $code < 0xD800 or $code > 0xDFFF ){
return chr(0xE0 + ($code >> 12))
. chr(0x80 | ($code >> 6) & 0x3F)
. chr(0x80 | $code & 0x3F);
}
}
return $invalid;
}
# Example:
echo "The Euro sign is ", utf8_bmp_chr(0x20AC);
Alcuni text editor, quando configurati per salvare i file in UTF-8, insistono a
mettere il BOM iniziale. Il BOM è una sequenza di 3 byte
"\xEF\xBB\xBF" che appare all'inizio del file a rappresentare il
codice Unicode non valido 0xFEFF. Il BOM non viene riconosciuto dal PHP e
interferisce con il suo funzionamento, quindi bisogna disabilitarlo.
Per maggiori informazioni sul BOM vedi www.unicode.org/faq/utf_bom.html#BOM.
Per maggiori informazioni sul BOM e il PHP, vedi il bug numero 22108 (http://bugs.php.net/bug.php?id=22108).
Sia PostgreSQL 8 che MySQL 5 riconoscono l'Unicode BMP, e quindi accettano solo UTF-8 fino a 3 byte per carattere, e danno un errore o si comportano in modo imprevedibile quando si forniscono sequenze UTF-8 non valide o fuori del range ammesso. Meglio allora sanificare le stringhe fornite dall'utente prima di inviarle al DB e prima di usarle in un qualunque modo. La funzione qui sotto filtra le sequenze UTF-8 valide per il BMP secondo le indicazioni dell'RFC 3629. Le sequenze non valide o non minimali, o vietate o che codificano caratteri Unicode che non stanno in 16 bit, vengono eliminate.
/**
* Filters and sanifies an UTF-8 BMP string. Only valid UTF-8 bytes encoding the
* Unicode Basic Multilingual Plane subset (codes from 0x0000 up to 0xFFFF with
* the exclusion of the range 0xD800-0xDFFF) are passed. Any other code or sequence
* is dropped. See RFC 3629 par. 4 for details.
* @param string $s Array of bytes supposedly containing an UTF-8 BMP encoded string.
* @return string UTF-8 BMP string.
*/
function utf8_bmp_filter(/*. string .*/ $s)
{
$T = "[\x80-\xBF]";
return preg_replace("/("
# Unicode range 0x0000-0x007F (ASCII charset):
."[\\x00-\x7F]"
# Unicode range 0x0080-0x07FF:
."|[\xC2-\xDF]$T"
# Unicode range 0x0800-0xD7FF, 0xE000-0xFFFF:
."|\xE0[\xA0-\xBF]$T|[\xE1-\xEC]$T$T|\xED[\x80-\x9F]$T|[\xEE-\xEF]$T$T"
# Invalid/unsupported multi-byte sequence:
.")|(.)/",
"\$1", $s);
}
Più avanti vedremo un esempio concreto che fa uso di questa funzione per validare l'input fornito dall'utente e prima di salvare le stringhe nel DB.
NOTA. Per una gestione completa dell'insieme Unicode, comprendente tutto il range fino al codice U+10FFFF, sono disponibili le funzioni chr() e sanitize() della classe it\icosaedro\utils\UTF8, che fa parte della libreria standard di PHPLint (www.icosaedro.it/phplint). Nella stessa libreria c'è anche la classe UString che permette di gestire stringhe Unicode in generale, evitando di pasticciare a basso livello con array di bytes. Rimane il fatto che non tutti i programmi esistenti oggi supportano il range completo Unicode al di fuori del BMP, quindi occorre fare un po' di attenzione.
|
ATTENZIONE!
Recentemente l'estensione mbstring del PHP ha aggiunto la funzione
|
Una questione terminologica: un charset è un insieme di caratteri e di ideogrammi, ciascuno con un proprio codice e senza alcun riferimento alla loro rappresentazione nella memoria di un computer; un encoding è invece una particolare rappresentazione in memoria dei codici di un certo charset.
Ad esempio, ASCII è un charset che definisce 128 simboli, alcuni stampabili e altri di controllo. Per rappresentare 128 simboli servono 7 bit, ma l'encoding tipica di questo charset usa un byte con il bit più significativo sempre a zero, che quindi viene sprecato.
L'ISO-8859-1 definisce circa 240 simboli, e la sua codifica tipica richiede un byte.
Un sorgente PHP tipicamente utilizza solo caratteri ASCII, per cui non si
presentano particolari problemi di encoding: un file ASCII è già anche un
file UTF-8 valido. La maggior parte delle librerie di funzioni e di classi
contengono codice puro e sono tipicamente file ASCII. Tuttavia PHP consente
di usare codici non ASCII sia negli identificatori, sia nelle stringhe
letterali, sia nel codice HTML che circonda il codice PHP. Semplicemente,
il PHP ignora la natura di questi codici e li interpreta letteralmente. E'
responsabilità del programmatore assicurarsi che il programma PHP, le pagine
generate e i dati letti e scritti sul DB mantengano un encoding definito.
Pertanto bisogna avere cura di scrivere tutti i sorgenti usando l'editor
impostato nella codifica scelta, altrimenti stringhe e nomi "uguali"
risultano diversi per il PHP, e la funzione stampa_piè_pagina()
definita in un file codificato ISO-8859-15 non potrà essere chiamata da
un file codificato UTF-8.
L'encoding di riferimento per noi sarà l'UTF-8 perché è il più generale usabile con PHP, ma le stesse considerazioni che faremo si applicano qualunque sia l'encoding scelta.
Vediamo ad esempio come la stessa stringa letterale si può scrivere in UTF-8:
echo "Caff\xC3\xA8 Brill\xC3\xAC"; echo "Caffè Brillì";
La prima forma utilizza l'ASCII, e i codici UTF-8 devono essere introdotti in forma esadecimale. Questa forma è necessaria se il text editor che si sta usando non supporta l'UTF-8. La seconda forma è più conveniente e sfrutta un text editor che ha il supporto per l'UTF-8. In entrambi i casi la rappresentazione nella memoria del PHP e l'output generato sono esattamente gli stessi, e le due stringhe sono lunghe esattamente 14 byte per 12 caratteri Unicode. Il PHP, almeno fino alla versione 5, non ha cognizione dell'encoding delle stringhe, e le stringhe sono solo sequenze di byte.
Attualmente PHP riconosce il file sorgente come una successione di byte, ed ignora completamente il problema dell'encoding. Tutte le parole chiave del linguaggio e i simboli speciali usano solo caratteri ASCII, mentre per gli identificatori e le stringhe si possono usare anche tutti gli altri byte di codici da 128 a 255. La conseguenza di questo comportamento è che l'interprete PHP legge sia sorgenti puramente ASCII, sia sorgenti ISO-8859, sia UTF-8 perché tutte queste codifiche hanno l'ASCII come sotto-insieme comune.
E' evidente che la codifica del sorgente PHP e quella delle pagine WEB generate devono corrispondere: se scrivo il sorgente con un text editor che usa l'ISO-8859-1 ma poi genero l'intestazione delle pagine mettendo l'UTF-8 nell'header HTTP, la conseguenza sarà che la pagina non verrà visualizzata correttamente. Il PHP lascia completamente alla responsabilità del programmatore di scrivere i sorgenti in modo coerente con una data codifica. E' bene pertanto fissare una volta per tutte l'encoding voluta e mantenere questa per tutto il nostro lavoro: text editor, sorgenti PHP, data base, ecc. devono concordare la codifica usata, altrimenti andremo incontro a problemi.
Siccome il PHP non ha cognizione dell'encoding usata, bisogna manipolare
le stringhe facendo attenzione a quello che si fa. Di norma le funzioni
di stringa della famiglia str*() lavorano a livello di byte,
e quindi sono utili per gli encoding ASCII e ISO-8859 e per manipolare
contenuti binari, ma non vanno bene per le codifiche multi-byte come l'UTF-8.
L'estensione mbstring (multi-byte string functions) è quello che
ci serve. Vediamo per punti alcuni suggerimenti utili.
setlocale(LC_CTYPE, 'C'); all'inizio
dei programmi. Il meccanismo delle variabili d'ambiente della serie LC_*
serve per istruire varie librerie di sistema sulla codifica usata nelle
stringhe. In definitiva, è un meccanismo per consentire ai programmi
esistenti e concepiti per il solo ASCII, di interpretare correttamente anche
un encoding diverso. Alcune funzioni del PHP come strtolower(),
strtoupper(), ucfirst(), il modificatore /w delle
PCRE, ecc. sfruttano questa impostazione.
Impostando LC_TYPE come suggerito qui, tutte queste funzioni penseranno che
stiamo usando solo puro ASCII e lascieranno in pace i codici "ASCII-esteso"
dell'UTF-8, evitando disastrose manomissioni.
trim(),
echo e printf funzionano senza problemi anche
con l'UTF-8. Per trasformare una stringa in un numero basta il typecast
(int)$s. Le indicazioni date qui e un po' di buon senso
dovrebbero bastare per capire quali altre funzionalità del linguaggio
dipendono o non dipendono dall'UTF-8 e quando è realmente necessario ricorrere
alle funzioni dell'estensione mbstring.
strlen($s) ritorna la lunghezza in byte della
stringa $s. La funzione mb_strlen($s, "UTF-8") ritorna invece
il numero di caratteri della stringa $s interpretata secondo l'encoding UTF-8.
In generale mb_strlen($s, "UTF-8") <= strlen($s) perché
i caratteri UTF-8 possono richiedere 2 o più bytes.
mb_substr($s, 3, 1). Per fortuna
raramente è necessario manipolare le stringhe a livello di caratteri.
Più spesso dovremo eseguire dei banali explode() in
corrispondenza degli spazi, oppure dovremo suddividere i campi di una riga
separati da virgole, o ancora useremo nl2br() per
rappresentare un testo. Si tratta di tutti casi in cui possiamo ignorare la
codifica UTF-8 e possiamo operare normalmente come se le stringhe fossero
puro ASCII.
preg_*() accettano il modificatore /u
per la codifica UTF-8, necessario per dire quanti byte occupa un carattere
. oppure un set [] o una parola \w
o un range {}. In certi casi, invece, è inutile porsi il
problema. Ad esempio, una espressione per validare un numero non richiede
particolari accorgimenti, dato che le cifre e gli altri simboli che possono
apparire in un numero sono tutti codici ASCII a un byte.
urlencode($s) per vedere cosa c'è dentro realmente.
A questo punto, sembra che scrivere un programma in grado di trattare le stringhe con una data codifica sia un compito lungo e delicato. In realtà non è così, perché la manipolazione delle stringhe si limita a ben pochi punti del programma che di solito sono un set di funzioni di validazione e formattazione ben definito, e tutto il problema viene ad essere isolato lì. Cambiare codifica del programma, se mai fosse necessario, alla fine richiede di intervenire solo al livello di questa libreria di funzioni di uso generale e non richiede di intervenire su tutto il programma.
Accedere ai files pone due ordini di problemi: la codifica dei nomi dei files e la codifica del contenuto dei files. Per quanto riguarda la codifica del contenuto dei files, siamo messi abbastanza bene: il PHP permette di leggere e scrivere il contenuto dei file con la grana del byte, e quindi, almeno in principio, abbiamo il pieno controllo di quello che scriviamo o leggiamo, per cui non mi dilungherò oltre.
C'è invece un problema con la codifica dei nomi dei file. Per esempio, per
aprire un file in lettura useremo qualcosa come
fopen("nome.txt", "r"). La documentazione omette però di
chiarire un punto importante: quale dev'essere la codifica del nome del file?
Se invece vogliamo scorrere il contenuto di una directory, allora useremo la
funzione dir("."), che ritorna un oggetto che a sua volta esibisce
il metodo read() che ritorna la prossima entrata da analizzare.
Anche qui, la documentazione omette di specificare qual'è la codifica del nome
del file.
In generale, la codifica da usare per i nomi dei file e per i nomi dei path dei file è data dalla variabile di ambiente LC_CTYPE, che in PHP si legge con la funzione setlocale() ponendo a zero il secondo argomento:
$ctype = setlocale(LC_CTYPE, 0);
Il valore di $ctype ha forma generale "language_country.encoding" dove encoding è la codifica usata per i nomi dei file. Per esempio, su Linux potremmo avere "en_US.UTF-8", mentre su Windows potremmo avere "english_United States.1252" su una macchina configurata con il locale occidentale, oppure "japanese_Japan.932" su una macchina giapponese. Nel primo caso la codifica dei nomi dei file è UTF-8, per cui non è richiesta alcuna trasformazione delle nostre stringhe perché sono già codificate UTF-8. Negli altri due casi dovremo tradurre le stringhe nella codifica Windows code page 1252 (charset occidentale simile, ma non uguale, all'ISO-8859-1 detto anche Latin1)oppure 932 (charset giapponese minimale).
Vediamo nel dettaglio come vanno le cose nei due mondi:
Nel mondo Unix e Linux i nomi dei file sono stringhe di bytes terminate dal byte zero (che perciò non può fare parte del nome stesso), mentre l'encoding è dato dalla variabile di ambiente LC_CTYPE. Quindi, per accedere ai file dovremo prima convertire le nostre stringhe UTF-8 nell'encoding del file system; se la nostra stringa contiene caratteri Unicode che non si possono rappresentare nell'encoding del file system, allora non potremo accedere a quel file. Viceversa, i file letti dal file system (per esempio con dir()) devono essere convertiti in UTF-8 da questo encoding: questo è sempre possibile farlo.
Per conoscere l'encoding correntemente configurata, basta dare questo comando da un terminale:
$ echo $LC_CTYPE en_US.UTF-8
Nel mondo Windows il file system usa la codifica UTF-16 per i file a cominciare da Windows 2000 (Windows NT usava il più limitato UCS-2, mentre MS-DOS e quindi Windows 95 usavano la codifica Windows code page ancora più limitata). UTF-16 significa che ogni carattere viene rappresentato con 16 bit, ma per le scritture ideografiche dei paesi orientali un singolo simbolo può richiedere due parole a 16 bit. Purtroppo, l'interprete PHP funziona nella modalità dei programmi "non-Unicode consapevoli" per cui usa ancora il vecchio sistema delle tabelle Windows code page.
La tabella di code page da usare per i programmi non-Unicode consapevoli si configura sal pannello di controllo Regional and Language Settings, tab panel Format (per impostare la proprietà del locale LC_CTYPE) e nel tab panel Advanced (per impostare la tabella di code page che traduce da UTF-16 a Windows code page e viceversa). Le cose vanno nel modo seguente:
Per accedere a un dato file, il programma PHP deve convertire la stringa del nome del file dalla codifica interna del programma (UTF-8, nel nostro caso) alla codifca Windows code page come data dalla proprietà LC_CTYPE. Le tabelle di Windows code page sono disponibili a questo URL: http://www.unicode.org/Public/MAPPINGS/VENDORS/MICSFT/WINDOWS/ Ad esempio, la tabella 1252 è usata nei paesi occidentali Italia inclusa, mentre la tabella 932 viene usata in Giappone. E' chiaro che se la nostra stringa contiene caratteri Unicode che non si possono rappresentare nel Windows code page corrente, allora quel file non può essere letto.
Per esaminare il file system, per esempio con la funzione dir(), dovremo fare la conversione opposta dei nomi dei file dalla codifica Windows code page alla codifica delle stringhe usata nel nostro programma PHP. Qui però sorge un'altra limitazione: Windows applica le tabelle di "best fit" per la traduzione da UTF-16 a Windows code page disponibili in http://www.unicode.org/Public/MAPPINGS/VENDORS/MICSFT/WindowsBestFit/ Quando un carattere Unicode non può essere tradotto, si hanno due casi: il carattere viene tradotto in un altro di simile aspetto, anche se diverso; oppure, il carattere non convertibile del tutto viene sostituito con un asterisco.
Per esempio, se sul file system c'è il un nome di file che usa ideogrammi giapponesi come "日本語.txt", questo nome di file è accessibile su di un computer giapponese che usa il code page 932, ma non è accessibile su di un sistema occidentale che usa il code page 1252. E viceversa per il file "Caffé Brillì.txt", che su di un sistema giapponese viene ritornato al programma PHP con le vocali senza accenti perché le vocali accentate non sono disponibili nella tabella di code page 932. Il programma PHP non ha modo di rilevare che il nome del file ritornato è stato
In conclusione, siccome PHP gira su Windows come programma "non-Unicode consapevole", e siccome non esiste un code page UTF-8, ci sono forti limitazioni all'uso dei caratteri non-ASCII nei nomi dei file.
La libreria standard di PHPLint fornisce la classe it\icosaedro\io\FileName (http://www.icosaedro.it/phplint/libraries.cgi?lib=stdlib/it/icosaedro/io/FileName.html) per risolvere in modo generale il problema della conversione dalla codifica interna al programma PHP alla codifica del file system e viceversa. La classe FileName fornisce essenzialmente due metodi: il metodo encode() per passare dalla codifca interna al programma PHP alla codifca del file system, e il metodo decode() per fare il viceversa. Entrambi si avvalgono della classe UString per rappresentare le stringhe Unicode. Entrambi i metodi sollevano eccezione IOException se la conversione non si può fare. Ecco un esempio di come si può usare questa libreria:
require_once "autoload.php"; use it\icosaedro\io\FileName; use it\icosaedro\io\IOException; use it\icosaedro\utils\UString; try { // Stampa la dir. di lavoro corrente anche se il path // contiene caratteri non ASCII: $cwd = FileName::decode( getcwd() ); echo "La directory di lavoro corrente è: ", $cwd->toUTF8(); echo "Contenuto della directory corrente:"; $d = dir("."); while( ($f = $d->read()) !== FALSE ) echo FileName::decode($f)->toUTF8(), "\n"; // Apre un file il cui nome contiene caratteri non ASCII: $fn = UString::fromUTF8("Caffé Brillì.txt"); $file = fopen( FileName::encode($fn), "w"); //... } catch( IOException $e ){ die($e->getMessage()); }
Le tastiere in circolazione non sempre permettono di generare il simbolo dell'Euro €. Ecco alcune alternative:
"€" se il text editor in uso lo consente,
oppure in ottale come "\342\202\254" oppure ancora in
esadecimale come "\xe2\x82\xac".
€.
Possiamo ignorare del tutto il problema dell'encoding dei testi e sviluppare i programmi in puro ASCII, pur rimanendo però capaci di gestire correttamente l'encoding dei dati, l'encoding delle stringhe, ecc. Semplicemente, il codice in sé sarà scritto in puro ASCII.
Se, invece, pensiamo di includere del testo non ASCII nel codice HTML, nelle
stringhe letterali, o negli identificatori, allora dovremo curare che tutti
i sorgenti e le pagine HTML siano codificate correttamente. Se, ad esempio,
in un file A.php scritto in codifica UTF-8 scriviamo una funzione che si chiama
immagine_più_didascalia($img,$testo) e poi includiamo questo
sorgente in un secondo file B.php scritto in codifica ISO-8859-1 che chiama
immagine_più_didascalia("spiaggia.jpg", "Eccomi al mare!");
otterremo un errore per funzione non definita: il PHP non sà in quale codifica
è stato scritto il sorgente, e si limita a confrontare i nomi delle funzioni
byte per byte.
Perché le cose funzionino bene bisogna assicurarsi che il text editor salvi i
sorgenti *.php con l'encoding UTF-8 senza BOM iniziale. Il BOM iniziale
non viene riconosciuto dal PHP e quindi viene inviato al browser: ciò non solo
è indesiderato, ma impedisce anche di impostare gli header HTTP con la
funzione header(). Verificare questo è molto semplice:
"\xC3\xA8". In Linux usare ad esempio
l'editor esadecimale di Midnight Commander, oppure il comando
hexdump -C prova.txt.
Per lo sviluppo in ambiente Unix e Linux, l'articolo Configurazione della tastiera (www.icosaedro.it/tastiera) contiene utili suggerimenti.
Riguardo invece ai nomi dei file, è bene rimanere limitati al puro ASCII perché altrimenti ci si espone a vari pericoli quando questi file verranno trasferiti sul server. Anche un banale trasferimento FTP potrebbe riservare sorprese e rendere inutilizzabile la nostra applicazione WEB.
Per raccomandazione W3C, i browser WEB dovrebbero lavorare internamente sempre in Unicode. Pertanto ogni browser può gestire tutti i caratteri internazionali e può acquisire dati in qualsiasi charset.
Ogni pagina WEB e ogni documento ricevuto deve contenere l'indicazione dell'encoding. Se non lo fa, il browser ha due alternative: tentare di dedurre l'encoding oppure basarsi su di una impostazione default. Ad esempio, Mozilla ha il menu View:Character Encoding con le opzioni Auto-Detect oppure UTF-8, ISO-8859-1, ecc. Ovviamente conviene realizzare i siti WEB in modo accurato specificando sempre il corretto encoding dei documenti, altrimenti ci si espone a fastidiosi fraintendimenti con pagine che vengono misteriosamente visualizzate bene su una macchina ma non sull'altra.
Riguardo ai problemi di visualizzazione e stampa dei caratteri esotici, anche se il browser ha interpretato correttamente questi caratteri o ideogrammi, non è detto che sia disponibile un font adatto che li contenga. In generale questo avviene per gli ideogrammi dei paesi asiatici, i cui font di norma non vengono installati nei computer occidentali. Coloro che sono in grado di leggere queste scritture dovranno installare il font adatto seguendo le istruzioni del proprio sistema operativo.
Un altro problema di visualizzazione si può avere quando le pagine HTML impongono l'uso di un determinato font che però non dispone di determinati caratteri o ideogrammi. In questo caso il browser dovrebbe sostituire i caratteri mancanti del font con quelli di un font simile, ma l'operazione non è né facile né priva di possibili ulteriori problemi di visualizzazione. Per quanto possibile è meglio non imporre il font nelle pagine, e lasciare che il browser e l'utente scelgano quello che ritengono più completo e più leggibile. Saranno le immagini a definire l'aspetto estetico delle pagine e a produrre gli effetti grafici originali non riproducibili con il testo.
Sia MySQL che PostgreSQL supportano il subset BMP a 16 bit dell'Unicode. MySQL 5 può usare internamente la codifica a 16 bit per carattere oppure la codifica UTF-8. PostgreSQL 8 usa internamente la codifica UTF-8.
MySQL permette di definire l'encoding con varia granularità a livello di data base, di tabella e di singolo campo. PostgreSQL, invece, permette di definire l'encoding solo a livello di data base nel suo insieme. Nel seguito vedremo degli esempi basati su PostgreSQL. Per creare il DB si dà il comando SQL seguente:
CREATE DATABASE mydb WITH ENCODING='UTF-8';
La parola UTF-8 che appare in questo comando va in realtà
intesa come "UTF-8 limitato al BMP".
In alternativa il data base si può creare da linea di comando:
$ createdb --encoding=UTF-8 mydb
$ psql -l
List of databases
Name | Owner | Encoding
-----------+----------+-----------
icodb | salsi | UTF8
master | salsi | SQL_ASCII
mydb | salsi | UTF8
postgres | postgres | LATIN1
template0 | postgres | LATIN1
template1 | postgres | LATIN1
(6 rows)
La figura qui sotto mostra il nostro DB creato con PgAdmin. Notiamo che l'encoding è effettivamente UTF-8.
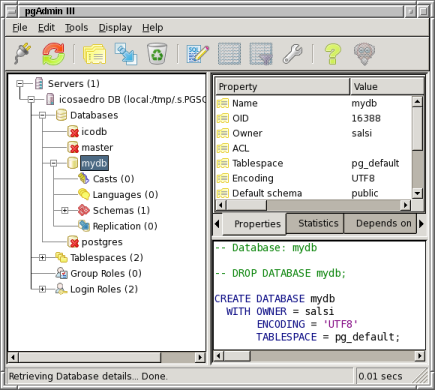
PgAdmin mostra il nuovo DB mydb creato con encoding UTF-8.
A questo punto tutti i campi di testo CHAR, VARCHAR e TEXT useranno la codifica UTF-8 fino a tre byte per carattere. Ad esempio, VARCHAR(50) significa che può ospitare fino a 50 caratteri Unicode, che corrispondono a fino 50*3 byte. I campi di tipo TEXT hanno lunghezza variabile e ospitano fino a 2 GB. Internamente PostgreSQL gestisce tutti questi campi come se fossero dei TEXT, salvo la diversa semantica che l'SQL standard impone sui CHAR e VARCHAR riguardo la lunghezza massima e la gestione degli spazi. In generale in PostgreSQL il tipo non-standard TEXT è il più comodo, e viene gestito in modo molto efficiente e compatto.
Non useremo nessuna impostazione particolare. Ci servirà solo l'estensione
mbstring per gestire le stringhe multi-byte, e naturalmente una
estensione per connetterci al nostro DB server. Come al solito, la funzione
phpinfo() ci fornisce tutte le informazioni necessarie. Riguardo
alla configurazione di mbstring, il file php.ini contiene diversi parametri
interessanti. Qui mostro le scelte che ho fatto io:
mbstring.language = neutral
Cosa voglia dire, non lo so, ma il valore "neutral" suona rassicurante.
mbstring.internal_encoding = UTF-8
La maggior parte delle funzioni del modulo mbstring ha bisogno di sapere l'encoding della stringa da elaborare. Con questo parametro impostato, tale informazione non è più necessaria e il nostro programma si semplifica un pochino. Io preferisco non avvalermi di questa possibilità, e nel codice indico sempre esplicitamente l'encoding che voglio, così che il programma viene a dipendere meno dalla configurazione del PHP del sito su cui gira. In generale, il codice dovrebbe sempre funzionare a prescindere dalla configurazione del php.ini.
mbstring.encoding_translation = Off
mbstring.http_input = pass
mbstring.http_output = pass
mbstring.detect_order = auto ; (non significativo)
Nelle intenzioni dei creatori del modulo mbstring, questo modulo dovrebbe essere in grado di determinare automaticamente la codifica delle stringhe ottenute dal browser e la codifica della pagina poi servita dal nostro programma, sicché tutte le operazioni di conversione da e verso la codifica usata internamente dal nostro programma (impostata conmbstring.internal_encoding) sarebbero del tutto automatiche. Sfortunatamente, non esiste un modo affidabile per determinare queste informazioni. Questo per due motivi: nessun browser inserisce le informazioni sulla codifica usata nei parametri forniti al programma; in generale il nostro programma riceverà le stringhe dei FORM codificate come lo era la pagina che conteneva il FORM stesso. Perciò se il FORM era in una pagina UTF-8, sarà questa la codifica delle stringhe ricevute. Come si vede, mbstring non ha modo di "ricordarsi" com'era fatta la pagina del FORM, e neppure l'informazione gli viene data dal browser. Il comportamento di mbstring in questo caso è ambiguo perché fa un tentativo di dedurre l'encoding basandosi sull'ultimo parametrodetect_order. Eseguire il debugging su di un sistema che esibisce un comportamento così aleatorio sarebbe un suicidio. In definitiva, con questo ambaradam non possiamo dormire sonni tranquilli. Pertanto, meglio lasciare queste opzioni disabilitate come indicato qui. La pratica suggerita da questo articolo propone di usare l'UTF-8 per tutto, per cui nessuna conversione è necessaria né in input né in output.
mbstring.substitute_character = 63 ; mette "?"
mbstring.substitute_character = none ; nulla
mbstring.substitute_character = long ; mette "U+xx"
Se l'input proveniente dal browser non viene validato accuratamente, oppure se il nostro programma manipola le stringhe come semplice sequenza di byte invece che tenere conto della loro effettiva codifica, è possibile che il modulo mbstring si trovi a dover manipolare stringhe di byte non compatibili con l'encoding attesa. Inoltre, quando si convertono delle stringhe da un encoding a un altro, determinati caratteri potrebbero non avere un equivalente nell'encoding di destinazione. Cosa fare, allora, dei byte o delle sequenze di byte non validi qualora comparissero dentro a una stringa? Questa opzione dice come comportarsi. Nel primo esempio il byte o la sequenza di byte non validi viene sostituita con il punto interrogativo (63 è il codice Unicode di questo carattere). Nel secondo esempio il byte o la sequenza non valida viene ignorato e non riportato nel risultato della elaborazione. Infine nel terzo esempio il byte o la sequenza non valida viene sostituito con "U+xx" dove xx è il codice esadecimale del byte. Naturalmente, se il nostro programma è fatto bene, le stringhe ricevute in input vengono subito sanificate, e inoltre il nostro codice non dovrebbe mai generare caratteri non validi. Pertanto questa opzione serve solo per il debugging.
mbstring.strict_detection = Off
Qualunque cosa voglia dire questo parametro, non mi interessa. Noi sappiamo cosa vogliamo e sappiamo come ottenerlo, per cui non ci serve nessun "detection" :-)
mbstring.func_overload = 0
Coloro che vogliono provare l'ebrezza degli automatismi possono provare un valore maggiore di zero, come suggerito dal manuale. Coloro che, come me, preferiscono capire quello che fanno e avere speranze concrete di risolvere i guai, meglio che lascino zero.
Per rendere il codice indipendente dalla configurazione del php.ini,
cosa particolarmente desiderabile per le librerie di utilità,
tutte queste direttive si possono impostare anche a run-time, fatta eccezione
per language, encoding_translation e
func_overload. Tipicamente il nostro programma dovrebbe
impostare la configurazione voluta, eseguire l'elaborazione e poi
ripristinare l'impostazione originaria, per esempio:
$old = ini_set("mbstring.substitute_character", "none");
# qui si esegue l'elaborazione
ini_set("mbstring.substitute_character", $old);In tutto il nostro discorso, il WEB server non è coinvolto: i testi passano attraverso di esso in modo trasparente.
Un sito WEB dinamico richiede l'interazione tra diversi elementi: il browser WEB, il WEB server che fa girare il PHP, e il DBMS. Per dialogare correttamente, questi tre soggetti devono concordare l'encoding dei testi che si scambiano. I vari passaggi sono mostrati nello schema qui sotto:
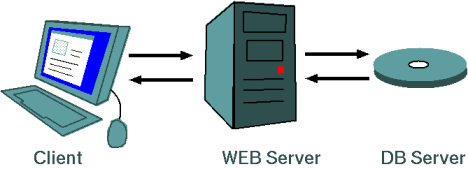
| I testi che compongono le pagine WEB fanno diversi passaggi tra browser, WEB server e data base. In un punto qualunque le cose possono andare storte... |
Il browser WEB lavora internamente con Unicode per la massima
generalità. Quando il browser riceve una pagina HTML dal server, con essa
viene specificato anche l'encoding, per esempio ISO-8859-1. Il browser
converte l'encoding della pagina in Unicode e quindi la presenta sullo
schermo. L'utente compila un FORM introducendo varie scritte nella lingua
che preferisce, magari usando qualche carattere o ideogramma "strano".
Quando l'utente esegue il submit, queste scritte vengono riconvertite
nell'encoding della pagina originaria, nel nostro esempio ISO-8859-1.
Siccome questo charset è molto limitato, è possibile che qualche carattere
Unicode non abbia un equivalente codice ISO-8859-1. In questo caso il
browser converte il codice alieno nella stringa &#ddd; dove
ddd è il codice decimale Unicode del carattere. E' evidente
che si tratta di un artefatto indesiderato. Per evitare questo problema
basta usare estesamente l'UTF-8, come descriviamo in questo articolo. Da
ora in poi supporremo di lavorare sempre e solo con UTF-8.
Il PHP riceve le stringhe come sequenze di byte senza tentare
di interpretarle. Siccome sappiamo che la pagina che conteneva
il FORM usava la codifica UTF-8, anche le stringhe acquisite
usano questa codifica. Le stringhe vanno acquisite a validate
come abbiamo descritto nell'articolo dedicato alla sicurezza (www.icosaedro.it/articoli/php-security.html).
Ripetiamo qui per comodità un esempio, dove il parametro POST di nome
s è un certo campo del FORM ricevuto dal browser:
$s = (string) $_POST['s'];
# Rimuovi codici ASCII 0-32,127:
$s = preg_replace("/[\\000-\\037\\177]/", "", $s);
# Forza codifica UTF-8/BMP:
$s = utf8_bmp_filter($s);
# Impone lunghezza massima di 50 char Unicode:
if( mb_strlen($s, 'UTF-8') > 50 )
$s = mb_strcut($s, 0, 50, 'UTF-8');
In questo esempio abbiamo limitato la lunghezza del campo a 50 caratteri
Unicode. Per troncare la stringa usiamo mb_strcut().
Notare che la stringa risultante $s potrebbe essere più lunga
di 50 byte, pur contenendo al massimo 50 caratteri Unicode: questo perché la
codifica UTF-8 può usare uno o più byte a seconda del carattere particolare
che compare nella stringa.
In generale per lavorare con Unicode dovremo sostituire nei nostri programmi
tutte le funzioni str*() con le loro controparti dell'estensione
mbstring mb_str*().
Dovremo dialogare con il data base server, tipicamente per scrivere o aggiornare o ricercare la stringa ricevuta dal client. La ricetta per fare questo è descritta da questo esempio:
$db = pg_connect("dbname=mydb");
pg_set_client_encoding($db, "UTF-8");
pg_query($db, "INSERT INTO una_tabella (un_campo) VALUES "
. "('" . pg_escape_string($s) . "')")
La funzione pg_set_client_encoding($db, "UTF-8");
assicura che il dialogo tra il PHP e il data base avvenga con l'UTF-8.
Per la ricerca sul data base, la ricetta è simile:
$db = pg_connect("dbname=mydb");
pg_set_client_encoding($db, "UTF-8");
$table = pg_query($db, "SELECT * FORM una_tabella");
A questo punto PostgreSQL si aspetta che tutte le stringhe inviategli siano in codifica UTF-8, ed inoltre avremo la certezza che tutte le stringhe ritornate dal DB con le query saranno sempre in codifica UTF-8 qualunque sia la codifica corrente dei dati nel DB.
Dovremo dialogare con il data base server, tipicamente per scrivere o aggiornare o ricercare la stringa ricevuta dal client. La ricetta per fare questo è descritta da questo esempio:
$db = @mysql_connect(/* ... */);
if( $db === FALSE ){
die("mysql_connect() failed: " . mysql_error());
}
$charset = "UTF8";
if( ! mysql_set_charset("UTF8") ){
die("mysql_set_charset($charset): unknown charset");
}
# Select the "test" DB:
$db_name = "test";
if( ! @mysql_select_db($db_name) ){
die("mysql_select_db($db_name) failed: " . mysql_error());
};
# Perform SQL query:
$query = "SELECT * FROM mytable LIMIT 10";
$res = @mysql_query($query);
if( $res === FALSE ){
die("mysql_query($query) failed: " . mysql_error());
}
La funzione mysql_set_charset("UTF8"); assicura che il dialogo tra
il PHP e il data base avvenga con l'UTF-8. E' importante notare che questa
funzione non genera alcun errore se il charset impostato non è valido, quindi
bisogna sempre verificare il valore di ritorno come mostrato dall'esempio.
Notare anche che bisogna proprio scrivere "UTF8" e non "UTF-8" con il trattino
perché quest'ultima scrittura non è riconosciuta da MySQL.
A questo punto MySQL si aspetta che tutte le stringhe inviategli siano in codifica UTF-8, ed inoltre avremo la certezza che tutte le stringhe ritornate dal DB con le query saranno sempre in codifica UTF-8 qualunque sia la codifica corrente dei dati nel DB.
Dovremo generare la risposta HTML, dipendente dal risultato della operazione precedente. Potrebbe essere la semplice notifica della avvenuta scrittura, oppure potremmo visualizzare un insieme di dati come risultato della ricerca sul DB. Comunque sia bisogna seguire queste regole:
header("Content-Type: text/html; charset=UTF-8");
Questo header è necessario se la pagina contiene caratteri non-ASCII, ma è necessario anche quando contiene un FORM dove l'utente ha la possibilità di inserire del testo, oppure contiene delle parti generate dinamicamente che possono a loro volta essere costituite da testo non-ASCII.
Se il programma PHP contiene delle stringhe o del testo, bisogna assicurarsi che il testo del programma sia anch'esso UTF-8. La maggior parte dei text editor e dei sistemi di sviluppo si possono configurare per usare l'UTF-8.
$s sia una stringa UTF-8 da visualizzare.
Per mostrarla come testo HTML dovremo codificare opportunamente i
caratteri speciali dell'HTML:
echo "La stringa è: " . htmlspecialchars($s);
$s deve apparire come attributo di una
entità, allora dovremo mettere anche le virgolette doppie:
echo "<input type=text name=s value=\"", htmlspecialchars($s), "\">";
echo "Il testo è: <textarea name=s>\n",
nl2br( htmlspecialchars($s) ),
"</textarea>";
\n dopo il tag di apertura,
in modo che eventuali righe vuote all'inizio della stringa vengano
preservate, come è stato discusso nell'articolo dedicato ai FORM (www.icosaedro.it/articoli/form.html).
Questo piccolo programma di test aiuta a verificare che l'encoding delle pagine generate dinamicamente sia quello giusto:
<?php
header("Content-Type: text/html; charset=UTF-8");
?>
<html>
<body>
<h1>Pagina di test per l'encoding UTF-8</h1>
Se le lettere accentate non appaiono correttamente,
è perché il nostro text editor non ha prodotto un
file UTF-8 corretto.
</body>
</html>
Alcuni ritengono utile definire l'encoding usata dal loro programma mediante una costante, magari definita in un file da includere in ogni pagina. In questo modo credono di avere generalizzato il loro programma in modo da supportare qualsiasi encoding, basta cambiare la costante:
define("ENCODING", "UTF-8");
Non fatelo, è perfettamente inutile. L'encoding UTF-8 è già il
massimo della generalità. Inoltre le pagine HTML statiche non si possono
parametrizzare con questa costante. Infine, scrivere "UTF-8"
è anche più breve che scrivere ENCODING.
Sono quelle prive di codice PHP, che spesso hanno estensione
.html oppure .htm. Indicare la codifica usata
per il testo è fondamentale, altrimenti il browser non può dedurla in
modo affidabile. Non si tratta solo di una questione di visualizzazione:
ricordiamo che se la pagina contiene un FORM allora i dati compilati ci
ritorneranno nell'encoding della pagina stessa. Ma se non siamo sicuri di
quale sia l'encoding della pagina, il risultato sarà alquanto confuso:
l'utente vedrà apparire strani simboletti, mentre al programmatore verrà
il mal di testa per sistemare il tutto.
Alcuni WEB server vengono configurati per aggiungere automaticamente una codifica default, tipicamente ISO-8859-1, ma in futuro troveremo più spesso UTF-8. L'unico modo per essere certi del risultato è imporre la codifica UTF-8 con un tag META, come in questo esempio:
<html> <head> <meta http-equiv="Content-Type" content="text/html; charset=UTF-8"> </head> <body> <h1>Pagina di test per l'encoding UTF-8</h1> Perché le lettere accentate e gli altri caratteri non-ASCII vengano mostrati correttamente, è necessario impostare l'encoding della pagina HTML. Il protocollo HTTP chiama erroneamente questo parametro "charset", ma "encoding" sarebbe la dizione più corretta. </body> </html>
Ovviamente la pagina HTML dovrà poi essere codificata UTF-8. La maggior parte dei text editor e dei programmi di sviluppo WEB sono perfettamente in grado di essere configurati per usare l'UTF-8. L'esempio qui sopra è un valido test per le pagine HTML statiche.
Abbiamo visto come impostare le cose perché il nostro server dia fuori le pagine nella giusta codifica. Ci sono molti modi in cui le cose possono andare storte, per cui serve uno strumento di verifica finale. Richiamare semplicemente dal browser una pagina per vedere se "viene bene" di solito non basta, e se qualcosa non funziona risulta difficile capire dove sta il problema, cioè se dobbiamo incolpare il gestore del server o il produttore del browser. Già poter suddividere le responsabilità tra client e server sarebbe un buon modo per dimezzare il campo di ricerca. Vediamo come fare.
Alcuni browser possono mostrare una pagina di informazioni. Ad esempio in Mozilla si clicca col destro e si seleziona la voce View Page Info, mentre in Opera c'è un utile plug-in che si chiama Developer Console ed è scaricabile dal sito del produttore. Mozilla mostra in chiaro l'header Content-Type, che è quello che ci interessa. Il plug-in di Opera mostra tutti gli header HTTP, incluso quello che ci interessa.
In generale, se questi strumenti non sono disponibili, si può sempre
ricorrere al buon vecchio programma telnet che ha anche la capacità
di collegarsi in TCP a qualsiasi porta, incluso la porta 80 dell'HTTP.
Supponiamo ad esempio di voler controllare la codifica della pagina
http://www.sito.it/doc/info.php. Il server è www.sito.it, la porta è l'80, e il path della risorsa è /doc/info.php.
Il comando telnet per collegarsi è il seguente. Le righe in grassetto sono
quelle che bisogna battere da tastiera e bisogna aver cura di rispettare
maiuscole e minuscole proprio cosí come appaiono:
$ telnet www.sito.it 80 Trying 12.34.56.78... Connected to www.sito.it. Escape character is '^]'. GET /doc/info.php HTTP/1.1 Host: www.sito.it (qui battere ancora enter per una riga vuota) HTTP/1.1 200 OK Date: Sat, 16 Feb 2008 15:21:29 GMT Server: Apache X-Powered-By: PHP 5 Last-Modified: Wed, 13 Feb 2008 14:28:27 GMT Transfer-Encoding: chunked Content-Type: text/html; charset=UTF-8 (qui riga vuota che delimita l'inizio del contenuto) 2D <HTML><BODY> Pagina di prova. </BODY></HTML> 0 Connection closed by foreign host.
La riga che interessa qui è la Content-Type, che ci conferma che la risorsa richiesta viene effettivamente ritornata con il tipo MIME e con l'encoding attesi. La stessa prova si può fare anche con le pagine statiche, con le immagini, e con qualsiasi altro documento. Notare che nel caso delle immagini verranno ritornati i dati binari, e questo potrebbe incasinare il telnet. L'importante è che le prime righe della intestazione HTTP rimangano visibili.
Dopo le righe della intestazione c'è una riga vuota e poi il contenuto della risorsa. Il "2D" che appare all'inizio della pagina HTML non deve preoccupare perché si tratta della codifica chunked a cui fa riferimento l'intestazione, per cui lo possiamo ignorare. E' possibile che il programma telnet non riconosca la codifica specifica della pagina, e del resto non ha alcun modo per rilevarla perché telnet non sa nulla dell'HTTP :-) Di conseguenza è possibile che appaiano simboletti a casaccio al posto delle lettere non-ASCII. Questo non ha alcuna importanza, perché ci interessa solo l'header.
Apache e PHP, www.icosaedro.it/articoli/cgi-php.html. Installare e usare l'interprete PHP con Apache.
FORM dell'HTML, www.icosaedro.it/articoli/form.html. Come realizzare i FORM dell'HTML: presentazione, acquisizione e validazione.
PHP Security, www.icosaedro.it/articoli/php-security.html. Come acquisire e validare l'input fornito dagli utenti.
PHP File Upload, www.icosaedro.it/articoli/php-file-upload.html e PHP File Download, www.icosaedro.it/articoli/php-file-download.html. In questi due articoli viene discusso il trasferimento dei file via HTTP, e viene anche discussa la questione dei nomi dei file che possono contenere alfabeti esotici.
PHPMailer-ico, www.icosaedro.it/phplint/libraries.cgi?lib=stdlib/net/sourceforge/phpmailer/PHPMailer.html. Classe di utilità che permette di comporre messaggi di posta elettronica correttamente codificati in UTF-8.
Esercizi di PHP, www.icosaedro.it/php/index.html. Panoramica sul linguaggio PHP con approfondimenti: sintassi, safety, security, applicazioni pratiche.
Configurazione della tastiera, www.icosaedro.it/tastiera. Come impostare l'ambiente di sviluppo per usare l'UTF-8.
Unicode Home Page, www.unicode.org.
UTF-8, a transformation format of ISO 10646, RFC 3629, www.faqs.org/rfcs/rfc3629.html. Questo documento del 2003 spiega la codifica UTF-8 fino a 4 byte per carattere. Rende obsoleto l'RFC 2279, che però prevedeva fino a 6 byte per carattere. Molto del software oggi in circolazione non è ancora stato aggiornato al riguardo.
UTF-8 and Unicode FAQ for Unix/Linux (www.cl.cam.ac.uk/~mgk25/unicode.html). Spiegazioni e riferimenti di approfondimento su Unicode, UTF-8 e compagnia.
PostgreSQL, www.postgresql.org.
| Umberto Salsi | Commenti | Contatto | Mappa | Home / Indice sezione |
An abstract of the latest comments from the visitors of this page follows. Please, use the Comments link above to read all the messages or to add your contribute.
2008-02-29 by Guest
Eccezionale
Stupendo meraviglioso chiarissimo.... ormai per me questo sito è un punto di riferimento... Complimenti[more...]
2007-06-01 by Guest
stupendo..
cìera un'informazione che non trovavo, ovvero quale fosse la codifica usata durante l'INVIO di un form! ho trovato la risposta,grazieee[more...]