
| Home / Indice sezione | www.icosaedro.it | |
 PHP Nomi dei file e Unicode
PHP Nomi dei file e UnicodeUltimo aggiornamento: 2012-03-19
Nei moderni file system i nomi dei file sono rappresentati dai codici Unicode. In Unix e Linux si usa di solito la codifica UTF-8 dell'Unicode, mentre in Windows si usa la codifica UTF-16. Sfortunatamente PHP non supporta le stringhe Unicode, per cui sorgono dei problemi quando si deve accedere a file o directory che contengono caratteri non-ASCII. Ad esempio, questi due file
Caffé Brillì.txt 日本語.txt
non sono in generale accessibili da PHP perché il primo riporta lettere accentate dell'alfabeto europeo occidentale, mentre il secondo contiene simboli ideografici giapponesi. Questo articolo vuole chiarire la situazione e propone una soluzione.
Il PHP accetta sorgenti scritti con un charset e un encoding arbitrari, purché i byte di valore da 0 a 127 rappresentino codici ASCII. Infatti tutte le parole chiave del linguaggio devono essere codificate in ASCII. Quindi vanno bene tutti i charset e le codifiche che hanno l'ASCII come subset: ISO-8859-* e UTF-8 vanno bene, mentre UTF-16 non funziona.
Le stringhe del PHP sono semplici sequenze di byte arbitrari, mentre non è specificato come questi codici si correlano ai caratteri di un particolare alfabeto. Per esempio:
$f1 = "Caffé Brillì.txt"; $f2 = "日本語.txt";
sono due stringhe, ma il contenuto esatto di queste stringhe dipende dal charset e dall'encoding del file di testo dove appaiono.
Nei sorgenti PHP le parole chiave del linguaggio sono codificate in ASCII (bytes da 0 a 127) mentre gli identificatori di costante, variabile, funzione e classe possono usare tutto lo psettro delle lettere, cifre e sottolineatura dell'ASCII più i byte da 127 a 255. Il PHP non ha idea di che cosa significano i byte da 127 a 255, ma si limita solo a confrontare i nomi a livello di byte per stabilire se due identificatori sono uguali o sono diversi. I nomi di funzione e di classe, e alcuni nomi di costante sono insensibili alla differenza tra lettere maiuscole e lettere minuscole del charset ASCII, ma questo non vale per i codici non-ASCII da 128 a 255, per cui ad esempio
function A(){}
function a(){}
dà errore perché la stessa funzione viene definita due volte, mentre
function À(){}
function à(){}
è valido perché si tratta di nomi diversi.
Lo scambio di nomi di file tra PHP e file system sottostante avviene attraverso stringhe. Per esempio, per creare un file useremo:
$f = fopen("Caffé Brillì.txt", "wb");
Come abbiamo detto, il nome del file è una sequenza di byte che dipende dal charset e dall'encoding del file di testo dove appaiono queste scritte. Ad esempio, se il file di testo è UTF-8, cioè il charset è Unicode e l'encoding è UTF-8, allora il codice di prima equivale al seguente:
$f = fopen("Caff\xC3\xA9 Brill\xC3\xAC.txt", "wb");
mentre se il file sorgente che abbiamo scritto è stato salvato come ISO-8859-1, allora il codice di prima equivale al seguente:
$f = fopen("Caff\xE9 Brill\xED.txt", "wb");
L'esatta codifica dipende da come abbiamo salvato il file del sorgente PHP. Ad esempio, in Notepad++ (vedi figura qui sotto) c'è il menu Format dove si sceglie l'encoding:
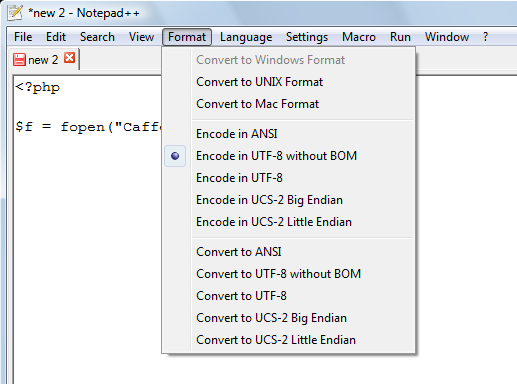
Cosa sia l'encoding ANSI lo sa solo l'autore del mitico Notepad++, ma
probabilmente si tratta del solito ISO-8859-1. L'UCS-2 non è compatibile con
PHP perché il linguaggio non riuscirebbe a riconoscere neanche le keyword.
"Encode in UTF-8" non va bene perché è sottinteso "...con BOM", cioè
all'inizio del file vengono messi i byte "\xEF\xBB\xBF" che
disturbano la visualizzazione delle pagine WEB. Non rimane che una scelta
soltanto: Encode in UTF-8 without BOM che è sano impostare come default
del programma.
Premesso tutto questo, quale file scrive esattamente l'istruzione precedente? Dipende dal sistema operativo e dalla sua configurazione:
fopen() viene
quindi passato dal PHP al sistema operativo senza alcuna modifica. Da sistema
Unix e Windows i nomi dei file si leggono con il comando ls oppure
con qualche programma di file management. Questi programmi interpretano i nomi
dei file a secondo del valore della variabile d'ambiente LC_CTYPE.
Per esempio, se questa variabile vale en_US.UTF-8, allora i nomi
dei file vengono presentati come UTF-8. Questo significa che il nome del
file realmente creato dipende dalla configurazione del sistema sul quale gira il
nostro programma PHP.
Conclusione. Se ci limitiamo ai nomi di file e ai path che contengono solo codici ASCII, allora non avremo problemi perché tutti i charset e tutti gli encoding di uso corrent hanno l'ASCII come sutto-insieme comune. Se, invece, vogliamo usare "caratteri estesi", allora dovremo procedere con grande cautela come spiegheremo nel seguito. Diciamo subito che dovremo stare attenti a codificare i sorgenti opportunamente, e poi dovremo sempre controllare la configurazione locale del sistema operativo per codificare correttamente i nomi dei file da leggere o da scrivere. Lo schema di lavoro è quindi questo:
Queste operazioni di conversione possono fallire per vari motivi, per cui dovremo tenere conto dei possibili errori.
In un mondo perfetto, i programmi dovrebbero specificare i nomi dei file come caratteri Unicode, e questo dovrebbe chiudere il discorso. Purtroppo il mondo non è perfetto: Unix e Linux non usano Unicode per default, mentre Windows usa Unicode ma PHP non è in grado di sfruttarlo e gira come programma "non-Unicode aware"". E'per questo ed altri motivi che esite l'intricato sistema delle preferenze di locale.
La funzione setlocale() permette di leggere la configurazione locale
per la codifica dei nomi dei file e dei testi in generale:
$ctype = setlocale(LC_CTYPE, 0);
Questa istruzione non imposta nulla, ma ritorna il valore della variabile LC_CTYPE. Su Unix e Linux potremmo ottenere
en_US.UTF-8
dove UTF-8 è l'encoding dei nomi dei file, mentre su Windows
potremmo ottenere qualcosa come
english_United States.1252
dove 1252 è la tabella di code page che traduce da byte a Unicode.
La forma generale delle variabili LC_* è:
language[_territory][.codeset][@modifiers]
dove:
language è il l'ISO639 language code;
territory è l'ISO3166 country code;
codeset è l'encoding ID, come "ISO-8859-1" oppure il numero di code page sotto Windows, che è esattamente quello che interessa a noi;
modifiers sono i modificatori di formato per date e numeri che non ci interessano.
Da Control Panel, Regional and Language Options possiamo impostare la lingua preferita, per esempio il giapponese, giusto per fare un esempio esotico interessante:
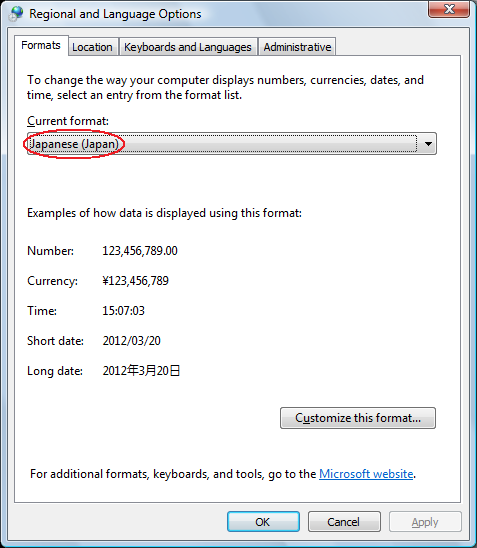
Imposta le preferenze di formattazione dei dati. I programmi usano questa
impostazione per formattare importi monetari, numeri, date e altro ancora.
Questo imposta anche il parametro LC_CTYPE al valore
"Japanese_Japan.932 dove 932 è la tabella di code page
giapponese. Sui computer occidentali tipicamente qui avremo invece qualcosa
come "english_United States.1252".
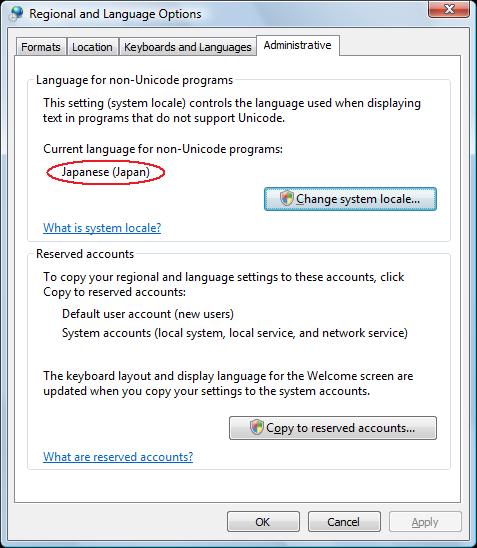
Con questa impostazione il sistema operativo converte automaticamente da 932 a
Unicode e viceversa i nomi dei file per i programmi non-Unicode compatibili,
come PHP. E' ovvio che questa impostazione deve corrispondere a quella
precedente. Questa impostazione NON imposta la variabile LC_CTYPE,
ma solo la conversione automatica che fa il sistema operativo.
Dopo aver cambiato questa impostazione è richiesto di riavviare la macchina.
| Umberto Salsi | Commenti | Contatto | Mappa | Home / Indice sezione |
Still no comments to this page. Use the Comments link above to add your contribute.